SRE Engineer (Oracle DB)
Detalles del trabajo
We are looking for you, if you:
- have experience in operating system administration (Linux or Windows),
- know key cloud proconcepts you can describe cloud-native
- understand and have knowledge about other stack layers – Network, Virtualization, Middleware, Databases,
- have good understanding of programming (preferred languages: Python, PoweShell, Golang),
- know how to use IaC/orchestration/automation tooling like Azure Pipelines, Ansible, Terraform,
- can identify and automate infrastructural management tasks using best infra-as-code practice,
- know key reliability engineering framework practices, consumer engineering idea and acronyms like SLI, MTTR and BCM are not just a couple random letters glued together.
English level - B2.
You'll get extra points for:
- value your time and don’t log in to host to run commands – Infra as a Code is your creed,
- do not like solving Incidents you prevent them from happening,
- like to always be step ahead and use new technologies,
- Energy and efficiency,
- Being a problem solver, not a spotter,
- Team player,
- Working with minimum supervision
Your responsibilities:
As the Site Reliability Engineering Department, we focus on four key topics:
- Run & Change
- Enablement
- Rapid Response
- Education
At your role you will mainly focus on:
Implementation of reliability across global platforms & services, global supporting tooling and entities:
- operating in strong cooperation with involved Enterprise Architects, other SREs & DevOps engineers,
- implementing observability measures via respective tooling of our critical business services,
- identifying service level objectives with associated indicators,
- look for and elimination of manual and repetitive task (commonly known as toil,
- planning and evaluating new releases of features within infrastructure environment (release trains).
Later on, focus will also be on other practices:
- mature major incident management process (major incident mgt, problem mgt, post-mortem & root-cause analysis),
- mature capacity planning & forecasting practice,
- mature reliability reporting,
- introduction of Error budgeting,
- knowledge management about spreading “reliability by design” concept and execution of all required reliability practices.
Information about the squad:
We are a Team of Infra admins who got tired of manual work and decided to move to Infra as a Code approach. We want to prevent, not repair and make our system Reliable. Taking best approach from Google and Microsoft we want to create Culture of SRE Engineering with focus on Design, Run Enable, Rapid Response, Educate and Review. Are you up for the challenge?
The role naming convention in the global ING job architecture will be “Engineer II”.
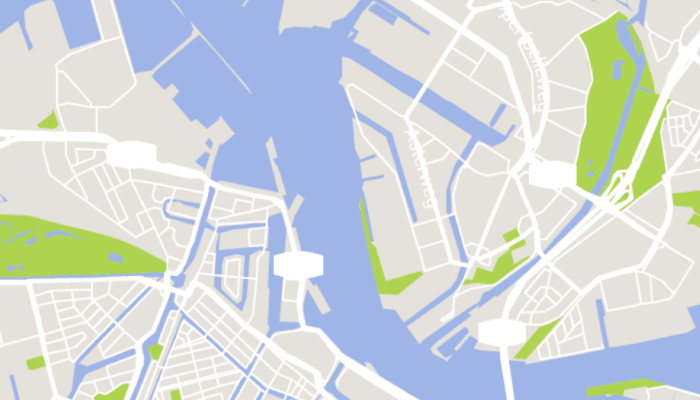 Your place of work
Explore the area
Your place of work
Explore the area
Questions? Just ask
ING Recruitment team
En ING queremos que las personas den lo mejor de sí mismas. Tenemos una cultura inclusiva donde todos pueden crecer y hacer la diferencia para nuestros clientes y la sociedad. Apoyamos siempre la diversidad, la igualdad y la inclusión. No toleramos ninguna forma de discriminación, ya sea por edad, género, identidad de género, cultura, experiencia, religión, raza, discapacidad, responsabilidades familiares, orientación sexual u otro motivo. Si necesitas ayuda o algún ajuste durante el proceso de selección o entrevista, ponte en contacto con el reclutador indicado en la oferta. Estaremos encantados de colaborar contigo para que todo sea justo y accesible. Haz clic aquí para saber más sobre nuestro compromiso con la diversidad y la inclusión
Más para ti
-
 Eventos ¡Ven a vernos en persona! May 02, 2024 Events
Eventos ¡Ven a vernos en persona! May 02, 2024 Events -
Banca minorista Explora carreras en Banca Minorista en ING. Empodera a clientes con herramientas innovadoras y construye experiencias excepcionales en banca digital. May 15, 2024 Article Expertise & Teams Retail Banking Related Content
-
Technology Únete a ING España en Tecnología. Aplica innovaciones tecnológicas a nivel global para mejorar la experiencia del cliente y proteger datos personales. May 15, 2024 Article Expertise & Teams
-
Risk Management Únete a ING España en Gestión de Riesgos. Identifica, evalúa y mitiga riesgos para proteger nuestros activos y apoyar decisiones empresariales estratégicas. May 15, 2024 Article Overview Expertise & Teams
-
Centros ING Únete a ING Hubs y transforma el futuro digital del banco. Oportunidades globales en TI, operaciones y más, en España y otros países. May 15, 2024 Overview ING Hubs
-
About ING Únete a ING, un banco global que da poder a las personas y a las empresas. Disfruta de una cultura diversa e integradora con oportunidades flexibles de trabajo y crecimiento. June 28, 2024 Article Culture
-
Business and Wholesale Banking specialism Únete al equipo de Business & Wholesale Banking de ING para ofrecer los mejores servicios financieros a clientes corporativos. Explora diversas funciones y deja huella en todo el mundo. August 12, 2024 Article Expertise & Teams Wholesale Banking Related Content
-
Audit Services at ING Únete a los Servicios de Auditoría de ING para impulsar la integridad y el cumplimiento en un equipo diverso y global. Explore puestos en distintas ubicaciones y contribuya a nuestro éxito. August 12, 2024 Article Expertise & Teams
-
Business support and Business Management Únete a ING España en Soporte y Gestión Empresarial. Ofrece apoyo operativo y estratégico, mantén el negocio en marcha de manera eficiente y efectiva. August 12, 2024 Article Expertise & Teams
-
Client and Business Services Únase a los Servicios a Clientes y Empresas de ING para mejorar la satisfacción de los clientes y agilizar los procesos. Ofrezca excelencia a nivel global e impulse la mejora continua. August 12, 2024 Article Expertise & Teams Related Content
-
Communications and Brand Experience Únete al equipo de Comunicación y Experiencia de Marca de ING para dar forma y compartir nuestra historia. Crea narrativas impactantes y mejora la presencia global de nuestra marca. August 12, 2024 Article Expertise & Teams
-
compliance Únete al equipo de Compliance de ING para combatir el fraude y la corrupción. Garantiza el cumplimiento de la normativa, protege nuestra reputación y actúa como nuestra brújula moral. August 12, 2024 Article Expertise & Teams Related Content
-
Corporate and Facility Services Únete al equipo de Servicios Corporativos y de Instalaciones de ING para crear espacios de trabajo innovadores que mejoren la productividad y fomenten la colaboración. ¡Causa impacto!
August 12, 2024 Article Expertise & Teams Related Content -
Customer Experience Únete al equipo de Experiencia del Cliente de ING para elevar cada punto de contacto y crear viajes excepcionales para los clientes que mejoren la satisfacción y la lealtad.
August 12, 2024 Article Expertise & Teams Related Content -
Data Modelling and Analytics Aproveche los datos para extraer ideas y fundamentar la toma de decisiones. Sea el motor analítico que impulse nuestros movimientos estratégicos. August 12, 2024 Article Expertise & Teams Related Content
-
Finance Únase al equipo de Finanzas de ING para gestionar nuestra salud financiera y navegar por las estrategias económicas, asegurando nuestra prosperidad en un panorama dinámico. August 12, 2024 Article Expertise & Teams Related Content
-
Human Resources Únete al equipo de Recursos Humanos en ING España. Ayuda a desbloquear el potencial de las personas y fomenta una cultura inclusiva para todos. August 12, 2024 Article Expertise & Teams Related Content
-
Group Treasury Explora oportunidades laborales en ING España. Únete a nuestro equipo en servicios financieros, gestión de riesgos y tecnología para innovar en la banca. August 12, 2024 Article Expertise & Teams Related Content
-
Innovation Únete a ING España en Innovación. Impulsa soluciones vanguardistas y crea un futuro lleno de creatividad, mejorando continuamente nuestros servicios. August 12, 2024 Article Expertise & Teams Related Content
-
Know Your Customer Únete a ING España en KYC. Comprende las necesidades de los clientes, asegura el cumplimiento normativo y juega un rol clave en la gestión de riesgos. August 12, 2024 Article Expertise & Teams Related Content
-
Legal and Corporate Governance Explora carreras en el área legal y de gobernanza en ING España. Únete a un equipo internacional y contribuye al crecimiento y soluciones creativas. August 12, 2024 Article Expertise & Teams Related Content
-
Leadership Únete a ING España en Liderazgo. Inspira equipos, guía nuestra visión y sé el catalizador que lleva a nuestra organización a nuevos niveles de éxito. August 12, 2024 Article Expertise & Teams Related Content
-
Procurement Únete a ING España en el área de Procurement. Gestiona relaciones con proveedores y optimiza procesos de compra para asegurar el mejor valor y calidad. August 12, 2024 Article Expertise & Teams Related Content
-
Relationship Management Únete a ING España en Gestión de Relaciones. Ofrece asesoría experta a clientes, construyendo relaciones duraderas y soluciones financieras a medida. August 12, 2024 Article Expertise & Teams Related Content
-
Transformation Únete a ING y lidera la transformación bancaria. Encuentra oportunidades en diversas áreas como riesgos, tecnología y operaciones en España. August 12, 2024 Article Expertise & Teams Related Content
-
Programa de talento internacional Descubre el International Talent Programme de ING. Una oportunidad global para desarrollar tu potencial con rotaciones y aprendizaje en banca.
August 13, 2024 Overview Early Careers: Global Graduate Programme Programmes -
Banca Mayorista Explore las oportunidades profesionales en Banca Mayorista en ING, donde ofrecemos a los clientes corporativos asesoramiento estratégico y soluciones bancarias eficientes. August 13, 2024 Overview Expertise & Teams Wholesale Banking Related Content
-
Oficinas de ING Descubre emocionantes oportunidades laborales en ING en más de 40 países. Únete y da forma al futuro de la banca con innovación y experiencia. August 13, 2024 Overview Expertise & Teams Related Content
-
Expertise & Teams En ING, nuestros diversos equipos destacan en todos los sectores bancarios. Desde la banca minorista hasta la banca mayorista, pasando por la gestión de riesgos y la tecnología, ofrecemos soluciones a medida y estrategias innovadoras. August 13, 2024 Overview Expertise & Teams Related Content
-
Working at ING Descubre un lugar de trabajo vibrante en ING, donde la colaboración, la sostenibilidad y el crecimiento te permiten tener un impacto positivo. ¡Únete a nuestra Cultura Naranja! August 13, 2024 Article Culture
-
Primeras carreras Descubre tu camino en ING con programas de talento, prácticas y formación diseñados para impulsar tu crecimiento profesional y personal. August 13, 2024 Overview Students & Graduates Related Content
-
Trabajar en ING en los Países Bajos Trabaja en ING Países Bajos, un líder financiero con una gran cultura laboral, beneficios competitivos y un compromiso con el progreso sostenible. August 13, 2024 Article Overview Location Spotlight Related Content
-
Trabajar en ING en Australia Trabaja en ING Australia: impacta a millones con soluciones innovadoras en banca, préstamos, seguros y más. Oportunidades en Sídney y Wyong.
August 13, 2024 Article Overview Location Spotlight Related Content -
Trabajar en ING Belgium Trabaja en ING Bélgica: sé parte de una cultura inclusiva y vibrante, con impacto en banca, sostenibilidad y tecnología. Sedes en Bruselas y más.
August 13, 2024 Article Overview Location Spotlight Employee Stories Related Content -
Trabajar en ING Alemania Tenemos más de 9 millones de clientes en Alemania que confían en nosotros, lo que nos convierte en el tercer banco del país. Nuestra actividad principal incluye cuentas de ahorro, hipotecas, productos de inversión, préstamos al consumo y cuentas corrientes para clientes particulares. August 13, 2024 Article Overview Culture Expertise & Teams Students & Graduates Benefits ING Hubs Early Careers: Global Graduate Programme Early Careers: Local Opportunities Location Spotlight Employee Stories
-
Trabajar en ING Italia Socio de confianza de millones de clientes corporativos y minoristas, ING está presente en Italia con sus dos líneas de negocio: Banca Mayorista y Banca Minorista. Nuestros casi 1.300 empleados se distribuyen entre nuestra sede central en Milán y nuestras sucursales y tiendas en 16 ciudades.
August 13, 2024 Article Overview Location Spotlight Related Content -
Trabajar en ING en Luxemburgo Únete a ING Luxemburgo y forma parte de un equipo que impulsa la innovación, la sostenibilidad y la excelencia en el sector financiero. ¡Descubre nuestras oportunidades! August 13, 2024 Article Overview Location Spotlight Related Content
-
Trabajar en ING en Filipinas ING Hubs Filipinas comenzó en 2013 bajo el nombre de ING Global Shared Operations, ofreciendo servicios internos de procesamiento para mercados financieros, préstamos y servicios de comercio y finanzas (TFS) a algunas de las sucursales de ING Wholesale Banking en Asia. August 13, 2024 Article ING Hubs Location Spotlight Related Content
-
Trabajar en ING en Polonia Descubre oportunidades emocionantes en ING Polonia, donde la innovación, sostenibilidad y desarrollo profesional se unen. August 13, 2024 Article Overview ING Hubs Location Spotlight Related Content
-
Trabajar en ING en Rumanía En ING en Rumania, ofrecemos interesantes oportunidades a través de dos entidades principales: ING Hubs Rumanía e ING Bank Rumanía. Juntos, forman una parte fundamental de las operaciones globales de ING, impulsando la innovación, la excelencia en el servicio al cliente y las finanzas sostenibles. August 13, 2024 Article ING Hubs Location Spotlight Related Content
-
Programa de Postgrado en Análisis Global (ITP) Descubre el poder de los datos con el Global Analytics Graduate Programme de ING y transforma la banca con análisis innovadores. ¡Aplica ya! August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Programmes
-
Trabajar en ING en Eslovaquia Únete a ING en Eslovaquia para impulsar la innovación, ofrecer servicios expertos y desarrollar tu carrera junto a un equipo de 1,400 profesionales en finanzas. August 13, 2024 Article Overview ING Hubs Location Spotlight Related Content
-
Cookie statement August 13, 2024 Overview
-
Programa Internacional de Talentos de Banca de Empresas Descubre el programa ITP de ING: un viaje de dos años con rotaciones globales para desarrollar tu carrera en la banca empresarial. August 13, 2024 Overview Students & Graduates Early Careers: Global Graduate Programme Early Careers: Local Opportunities Related Content
-
Centros de Filipinas Descubra ING Hubs Filipinas - un centro global de TI, finanzas, gestión de riesgos y análisis de datos, que da soporte a 40 países con más de 4.800 empleados. August 13, 2024 Overview ING Hubs Related Content
-
Polonia Hubs Descubra diversas oportunidades profesionales en ING Hubs Polonia, donde la tecnología, la gestión de riesgos y la analítica impulsan la innovación y la excelencia. August 13, 2024 Overview About ING Business ING Hubs Related Content
-
Romania Hubs Explora interesantes oportunidades profesionales en ING Hubs Rumanía, que ofrece puestos tecnológicos, de riesgo y de datos para potenciar la innovación global y la excelencia en el servicio al cliente. August 13, 2024 Overview ING Hubs Related Content
-
Hubs de Eslovaquia Scoprite le opportunità di carriera presso ING Hubs Slovakia, dove supportiamo il corporate banking con servizi esperti in tecnologia, gestione del rischio e analisi. August 13, 2024 Article ING Hubs Related Content
-
Turquía Hubs ING Hubs Türkiye ofrece servicios de tecnología y análisis de datos con un equipo de expertos en Estambul, dentro del grupo ING. August 13, 2024 Article ING Hubs Related Content
-
Banca mayorista en EMEA Descubre oportunidades en Banca Mayorista en ING. Únete a un equipo global que impulsa el crecimiento con soluciones innovadoras y sostenibles. August 13, 2024 Article Expertise & Teams Wholesale Banking Related Content
-
Programa Internacional de Talentos en Finanzas Únete al International Talent Programme de Finanzas en ING. Desarrolla habilidades estratégicas y lidera decisiones clave para un crecimiento sostenible. August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Related Content
-
Banca Mayorista en APAC Únete a ING, líder en banca mayorista en APAC. Ofrecemos innovación, soluciones personalizadas y oportunidades globales de carrera. August 13, 2024 Article Expertise & Teams Wholesale Banking Location Spotlight Related Content
-
Recursos Humanos Programa Internacional de Talentos Comienza tu carrera en RRHH con el Programa de Talento Internacional de ING. ¡Adquiere experiencia global y afronta retos reales! August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Related Content
-
Operaciones y Cambio Programa Internacional de Talentos Únete al Programa Internacional de Talento de ING para impulsar innovación y cambio, superar desafíos y construir una carrera en un banco global. August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Related Content
-
Programa internacional de talentos de banca minorista Únete al ITP de Banca Minorista en ING. Impacta a millones de clientes, desarrolla soluciones innovadoras y da forma al futuro de la banca.
August 13, 2024 Article Students & Graduates Retail Banking Early Careers: Global Graduate Programme Related Content -
Programa Internacional de Talentos para el Riesgo Únete al ITP de Riesgos en ING. Aprende a equilibrar riesgos y oportunidades, protege el futuro financiero y toma decisiones estratégicas clave.
August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Related Content -
Programa Internacional de Talentos Tecnológicos Únete al Programa Internacional de Talento Tech de ING: un programa global de 2 años para transformar el futuro bancario con tecnología innovadora. August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Early Careers: Local Opportunities Related Content
-
Programa Internacional de Talentos de Banca Mayorista Únete al ITP de Banca Mayorista en ING. Asesora a grandes clientes, gestiona acuerdos clave y aprende en un entorno corporativo dinámico y global.
August 13, 2024 Article Students & Graduates Early Careers: Global Graduate Programme Related Content -
Diversity Inclusion and Belonging ING fomenta una cultura de diversidad, inclusión y pertenencia a través de seis dimensiones -Discapacidad, Género, Generaciones, LGBTQI+, Raza y Etnia, y Cultura- a nivel mundial. August 14, 2024 Article Diversity, Inclusion & Belonging
-
Security Únete a ING España en Seguridad. Protege personas, activos e información contra amenazas y ayuda a mantener la confianza de nuestros clientes. August 21, 2024 Article Expertise & Teams Employee Stories Related Content
-
June 25, 2025





















































Jobs for you
No jobs viewed
No jobs saved